| compiler | gcc 3.3 | CW 9.3 | VC++ 2003 | ICC 8.1 | ||
|---|---|---|---|---|---|---|
| os | OS X 10.3.6 | WinXP SP2 | ||||
| cpu | G5 2.0 | P4 2.8 | PM 1.6 | P4 2.8 | PM 1.6 | |
| multiply add | 2000 | 2000 | 641 | 714 | 493 | 500 |
| inner product | 909 | 909 | 709 | 1250 | 714 | 909 |
| polynomial | 667 | 714 | 337 | 313 | 355 | 323 |
| hypotenuse | 345 | 370 | 214 | 131 | 213 | 134 |
| complex multiply add | 500 | --- | --- | --- | --- | --- |
| predicate | 2000 | 1111 | --- | --- | --- | --- |
| slicing | 270 | 238 | --- | --- | --- | --- |
| power | 60.6 | 50.3 | --- | --- | --- | --- |
| trigonometric | 39.7 | 71.9 | 20.9 | 15.3 | 30.9 | 22.9 |
Autovectorization promises the power of SIMD without the pain of SIMD. An autovectorizing compiler, such as Intel ICC 8.1 or gcc 4.0, will magically convert your scalar loop code into vector instructions without you having to do it yourself. Unfortunately, vectors are finicky customers — they want to be aligned properly, ordered sequentially in memory and fed branchless code for best performance. The autovectorizer has to discover these patterns in your code that may or may not be there — an uphill task for a mere machine.
macstl offers something better than autovectorization and manual vectorization. Use the inherently parallel, standard construct of valarray, and macstl has enough information to align, order and unbranch the generated code. The proof is in the running — pitting macstl 0.2.1 against its first autovectorizing contender, Intel ICC 8.1.
| compiler | gcc 3.3 | CW 9.3 | VC++ 2003 | ICC 8.1 | ||
|---|---|---|---|---|---|---|
| os | OS X 10.3.6 | WinXP SP2 | ||||
| cpu | G5 2.0 | P4 2.8 | PM 1.6 | P4 2.8 | PM 1.6 | |
| multiply add | 3.4 | 3.4 | 1.4 | 2.4 | 1.9 | 2.6 |
| inner product | 2.7 | 2.7 | 3.3 | 4.5 | 1.1 | 0.9 |
| polynomial | 2.3 | 3.2 | 1.0 | 1.4 | 1.4 | 2.25 |
| hypotenuse | 4.1 | 6.9 | 4.6 | 5.1 | 2.1 | 1.6 |
| complex multiply add | 3.2 | --- | --- | --- | --- | --- |
| predicate | 2.8 | 2.0 | --- | --- | --- | --- |
| slicing | 0.84 | 0.76 | --- | --- | --- | --- |
| power | 6.7 | 5.4 | --- | --- | --- | --- | trigonometric | 11.7 | 16.2 | 6.2 | 2.8 | 15.6 | 8.7 |
In terms of raw speed (thousand operations per second) for macstl-generated code, ICC 8.1 loses to VC++ 2003 in the simple multiply add and inner product, draws even on polynomial and hypotenuse, and wins in the difficult trigonometric — as befits its reputation as a powerhouse compiler.
What’s more interesting though, is how many times faster macstl was over the scalar loops. In the ICC case, several of the scalar loops were autovectorized by the compiler, yet macstl was faster than the autovectorizer in all cases except one — the inner product on a Pentium M 1.6Ghz.
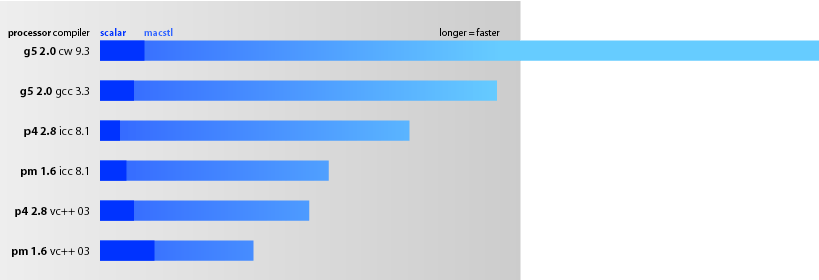
In fact, the difficult trigometric test autovectorized the worst: 15.6x vs. 6.2x on Pentium 4 2.8 Ghz — macstl inlined its specially tuned trig functions, while ICC generated slow calls to an external DLL. I’ve drawn the trigonometric test for your reference at the top of the page; as you can see, you get more mileage out of macstl!